Understanding the Bitmovin Encoding Object Model
Introduction
This tutorial describes the various objects that make up a Bitmovin encoding, how they interrelate, and how they are created and manipulated through the APIs and SDKs. It will help you understand the necessary foundations to become an efficient Bitmovin video developer.
In the next few sections, we will go through a high level overview of the fundamental objects that model an encoding workflow.
APIs and SDKs
But first, let's quickly talk about the relationship between these objects and the APIs that you use to instantiate them. The Bitmovin solution at its core is a platform that exposes an HTTP-based REST API for interaction with other systems, in particular your own. A number of endpoints are provided to create, retrieve and delete configuration objects and trigger the workflows. The objects manipulated by each endpoint follow models that are defined in a specification(*1). Most of the time, you will use one of our SDKs to interact with the platform. The role of the SDKs is fundamentally to allow you to work with the model, instead of having to work with the REST API directly. Their main tasks is to call the APIs for you, and in doing so to translate your objects into the appropriate JSON payloads sent in the HTTP requests, and translating the JSON responses back into those objects. Code completion and type checking are some of the advantages of this approach, all allowed by the strict modelisation of the solution.
When you browse the API reference, you are presented with the models associated with each endpoint. Click the Model hyperlink to see them.
Tip: you'll often find that the payload for the "create" (POST) request for any particular endpoint provides the clearest representation of one of the fundamental models associated with that endpoint. Indeed, the "list" and "get" (GET) requests often return multiple objects and additional request-level information in their responses and therefore get wrapped into other models.
Document conventions
Some of the objects used (actually many of them) do not have endpoints dedicated to them. They are just "internal" models that are combined into more complex ones managed through these endpoints.
To try and make the text below clear and provide some disambiguation of often used terms, we will adopt the following notation:
Objectrefers to one of our models. The plural formObjectsis just used as required for the text to read as correct English and does not refer to a different model!- These "internal" models that are not managed through dedicated endpoints will be indicated as
Object*the first time they appear. - Some models are high level and get "specialised" before being exposed as different actual endpoints. We'll note those as
Object^the first time they are introduced. Developers could think of them as prototypes or superclasses.
Finally, we use singular or plural form interchangeably in the text below, for clarity of the expression, but both forms refer to the same object, ie. Input == Inputs
Principal Objects
There are a number of objects that you will use every single time you work on an encoding workflow. They are the following:
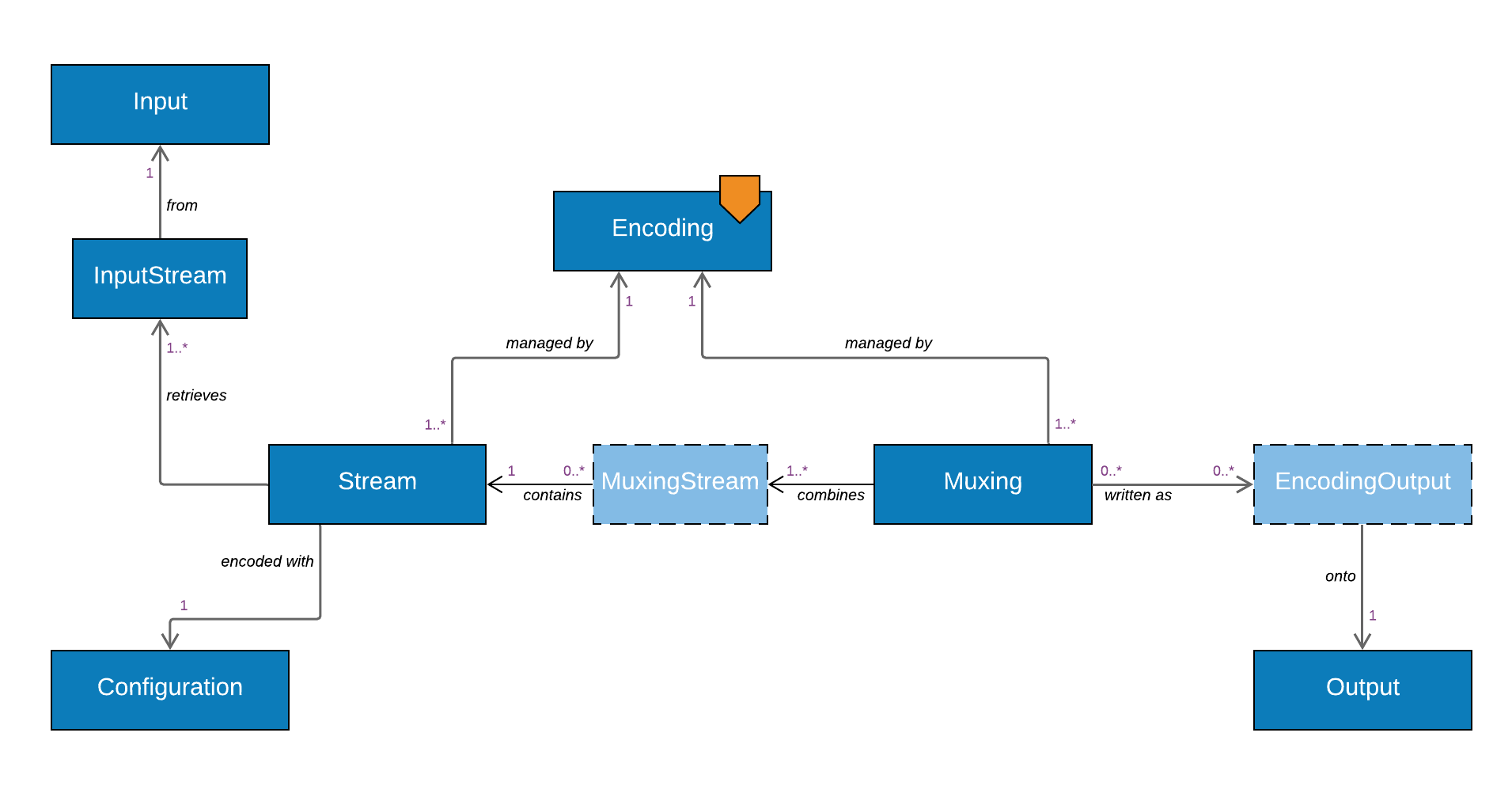
In this diagram, boxes with solid border represent objects associated with API endpoints, dotted boxes are the "internal" models. Arrows represent the direction of dependencies. Orange markers are added to the objects whose endpoints have web methods used to trigger the associated generation workflows
-
An
Input^represents a service (or server) that will be connected to in order to access the files or livestreams that will be ingested. There are implementations of this object into specific ones for different service providers, such as S3 (S3Input), SFTP (SftpInput) or RTMP (RtmpInput). (full list) -
Similarly, an
Output^is a service or server that will be connected to in order to write files or livestreams generated by the encoder. There are multiple implementations of this object as well, such as GCS (GcsOutput) or Akamai MSL (AkamaiMslOutput). (full list) -
An
Encodingis the top-level object when it comes to an encoding workflow, and is the one to which will be associated all other objects that create the chain between thoseInputandOutputservices. -
A
Streamrepresents the video (or audio, caption, etc) data itself, the elementary stream(*2) which will be generated by the encoder. AStreamneeds the following relationships to be functional:- A
Streamwill be encoded from one or multiple input streams. These are retrieved from files (or from a livestream) located on one of theInputs.InputStreamsare used to define those. There are different specialisations, based on the type and function of the input stream used to make the encoding. The principal ones areIngestInputStream,FileInputStream, and there are others used to define manipulations of input streams (such as concatenation, trimming, audio mixing, etc.). AStreamcan have more than oneInputStreamassociated with it. - The
Streamwill be encoded with a codec, according to a particularConfiguration^, which will set all the codec parameters (such as resolution, bitrate, quality settings, etc.). There are implementations of the object specific for each codec, eg.H264VideoConfiguration,Eac3Configuration, etc. (full list)
- A
-
Multiplexing (in short: muxing) is the process of combining encoded bitstreams into the containers that can be written to file or streamed as livestreams. The
Muxing^objects represent those containers. There are different specialisations ofMuxingsfor different containers, such as for fragmented MP4 (Fmp4Muxing), progressive TS (ProgressiveTsMuxing) or MP3 (Mp3Muxing).Muxingshave the following fundamental relationships:- A
Muxingcan contain one or multipleStreams. The association is done throughMuxingStream*objects - The
Muxingscan be written as files or livestreams onto multipleOutputservices at the same time. To make the association between those objects, and provide the necessary additional information (such as output paths, filenames and access permissions), we useEncodingOutput*objects. AMuxingcan have more than one.
- A
We now have all the fundamentals pieces in place that chain together. Let's summarize it:
In short...
An Encoding represents a workflow allowing the Bitmovin encoder to grab one or more InputStreams from Input services, encode them with codec Configurations into Streams, multiplex them into Muxings and output them onto Output services in locations defined by EncodingOutputs
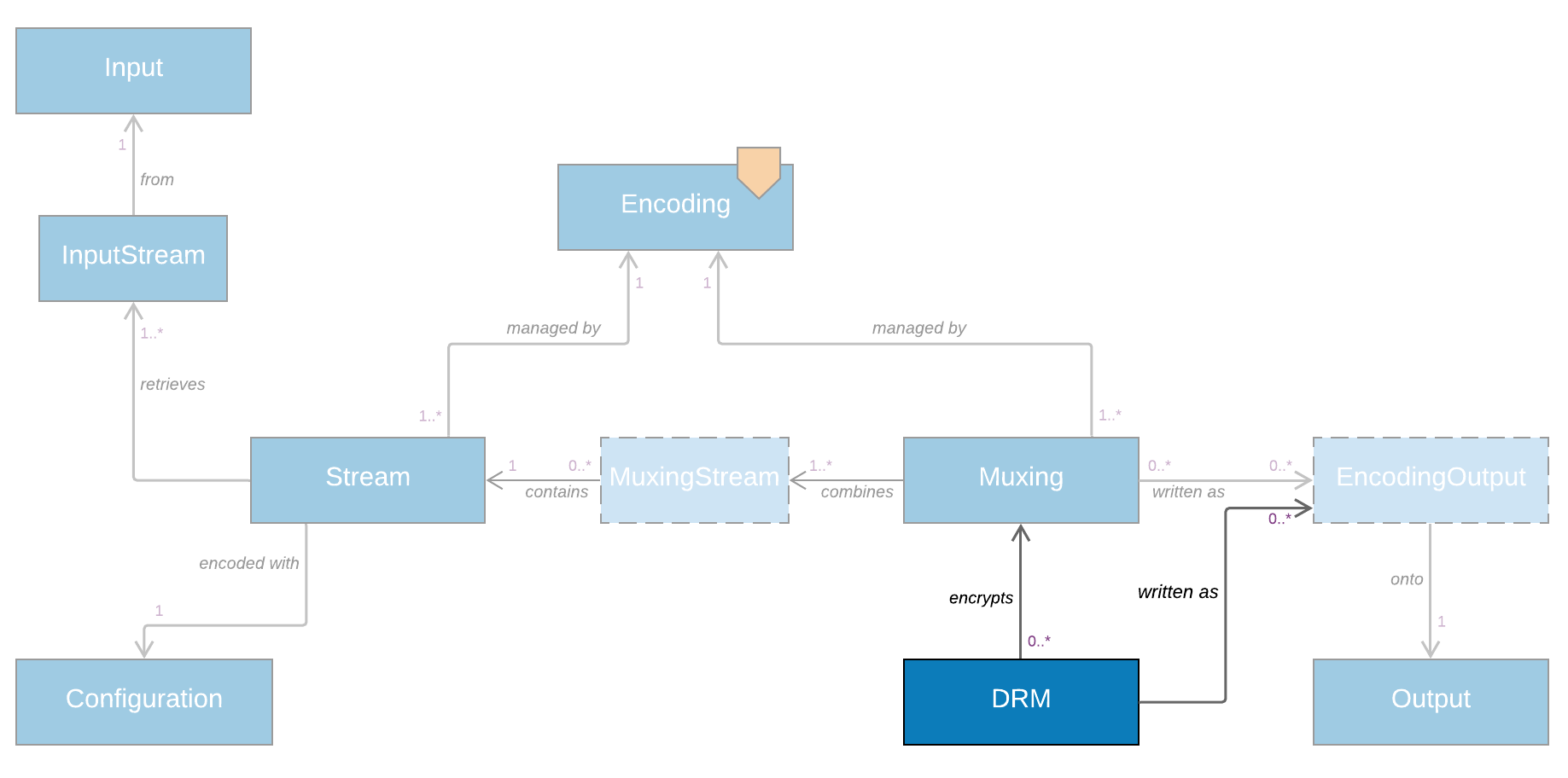
DRM
Everyone's favourite topic and the object of primal fears among video developers... At least the modelling of it is quite simple: A Drm^ object contains all the information required to configure the encryption of a Muxing. It has different implementations for different DRM methodologies such as CencDrm, FairplayDrm, ClearKeyDrm, etc.
The Drm object also links to Output services (via EncodingOutput objects), to represent the encrypted version of the files or livestreams to be generated. One of the great advantages of this model is that since the Muxing can now be written both as an unencrypted version (through its own link with an Output) and as an encrypted one (via the Drm object). Perfect if you want to send the DRM'ed content to your origin service, and the clear one to long-term storage!
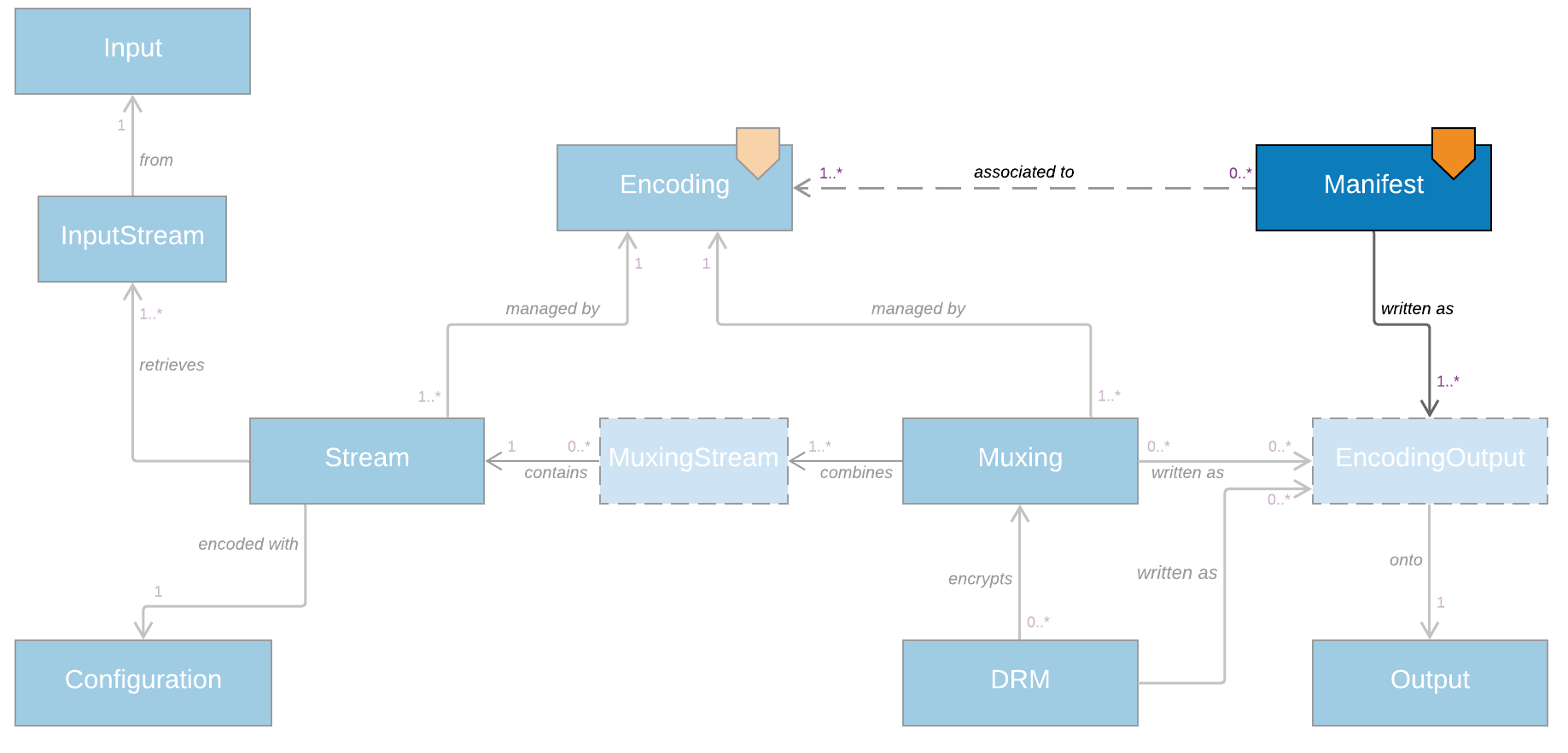
Adaptive Streaming
When considering adaptive bitrate (ABR) streaming, there is another concept to add to the previous ones. There is a component in the Bitmovin solution that is distinct (but closely related) to the encoder: the manifest service. It is in charge of writing the manifest files that associate multiple generated files and streams into payloads that an ABR player can consume and stream.
Numerous new objects are used to model ABR formats, worth a dedicated tutorial, but one in particular needs highlighting here:
The Manifest^ object is used to represent those, through implementations such as HlsManifest, DashManifest and SmoothStreamingManifest. It has the following relationships:
- To
Outputservices, viaEncodingOutput, just like before. - To one or more
Encodings, from which it will link (indirectly) to theMuxingsandStreamsthat are combined as individual representations (or renditions) for the ABR stream.
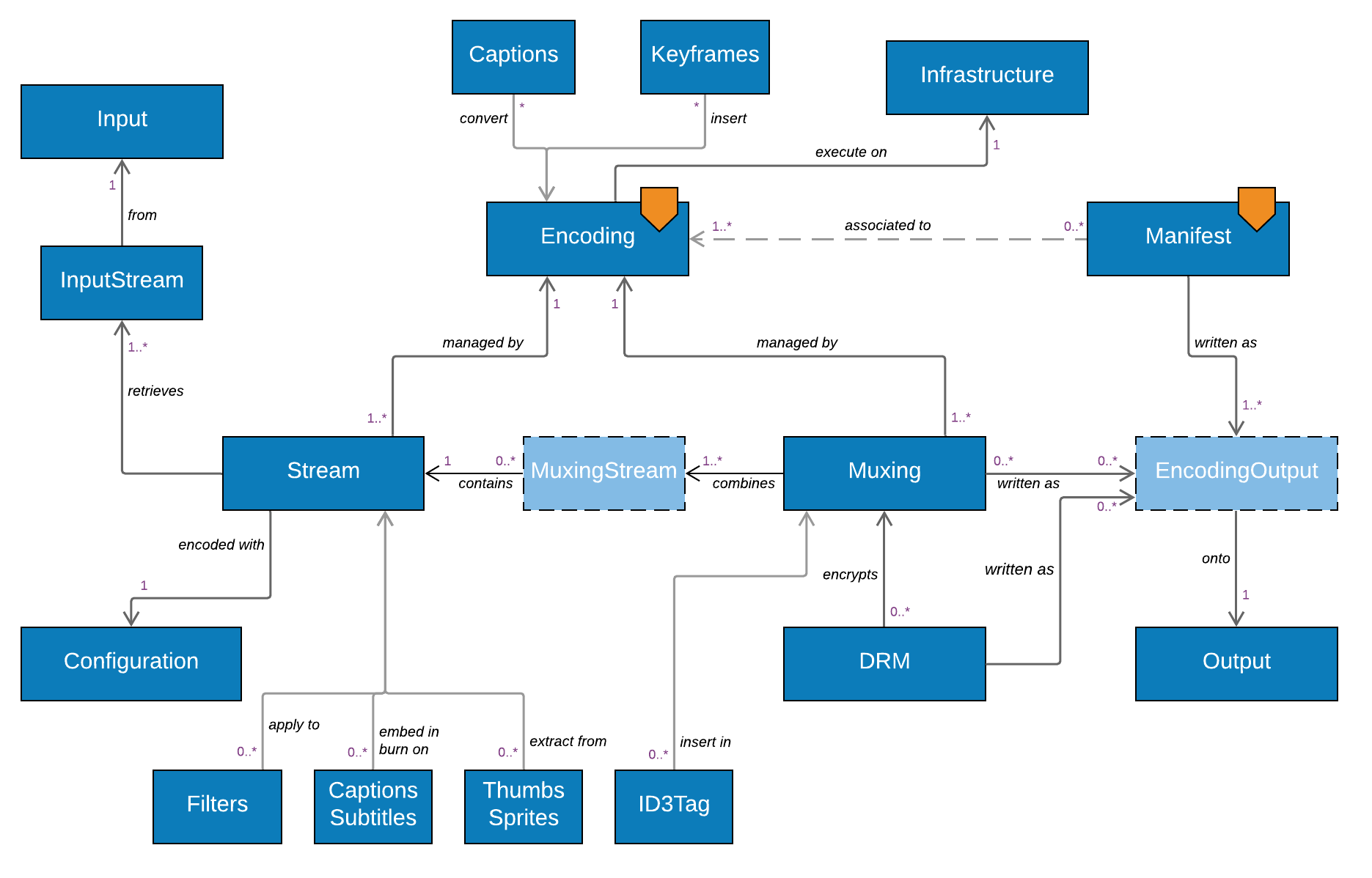
Infrastructure
At Bitmovin, we are proud to have engineered an encoding solution that works very much the same way, whether used in one of our managed clouds (whether on Amazon AWS, Google GCP or Azure), on our customers' own clouds, or even on on-premise infrastructure. The object model reflects that, by allowing an Encoding object to be linked with infrastructure objects such as KubernetesCluster or AwsAccount to simply control where a particular encoding will be performed.
And also...
There are loads of other objects that can be used to create more complex encoding configurations. Some of the ones worth highlighting:
Filter^objects are used to apply a transformation onto aStream. For example, aWatermarkFilterwill embed an image into a video, aDeinterlaceFilterwill turn an interlaced video into a progressive one, anAudioMixFilterwill allow you to remap audio channels. One or multipleFiltersare applied on aStreamthroughStreamFilters*, which also define their order of application.ThumbnailandSpriteobjects define the way in which thumbnails and sprites will be captured from aStreamand via whatEncodingOutputthey will be written to anOutputservice.SidecarFile^objects control the way that additional files retrieved from anInputcan be pushed to one or moreOutputs (via anEncodingOutput).WebVttSidecarFileis a prime example of it.- A number of objects handle subtitles, generally by connecting to an
Inputto retrieve a file or extract a stream, and either embedding them into aStreamor aMuxing, or converting them and transferring them through anEncodingOutputto anOutput, eg.SccCaption,TtmlEmbed,ConvertSccCaption,WebVttEmbed,WebVttExtract,BurnInSubtitleSrt, etc. Keyframeobjects are used to control the insertion of keyframes into anEncodingat a high level, whereasId3Taginsert ID3 tags intoMuxings.- And pretty much every single object that is managed through an endpoint also supports the ability to have
CustomDataassociated with it, in the form of key/value pairs
Footnotes
(*1) - We use the OpenAPI 3.0 standard to define our API spec. It offers many advantages, including the ability to generate SDKs automatically!
(*2) - It is worth stopping for a minute on this word: "stream". It has the potential to be very ambiguous, as it is used extensively both by developers and video engineers to mean more than one thing. Here are some of them that you should know and be able to differentiate. The context will help you differentiate between them.
- the elementary stream, the output of an encoder before multiplexing takes place. By and large that is what our
Streamobject relates to. If you look at the output of a tool like ffprobe or mediainfo for a given file, you will see that it lists the streams contained in that file. - the generic term used to portray the act of transmitting and receiving media, such as a "live stream", or an "ABR stream".
- In Java 8, the awesome new functionality that allows us to use functional-style operations on collections. You may see those in our Java SDK examples.
Updated 6 months ago